The need of an flexible app to evaluate algorithms with high performance
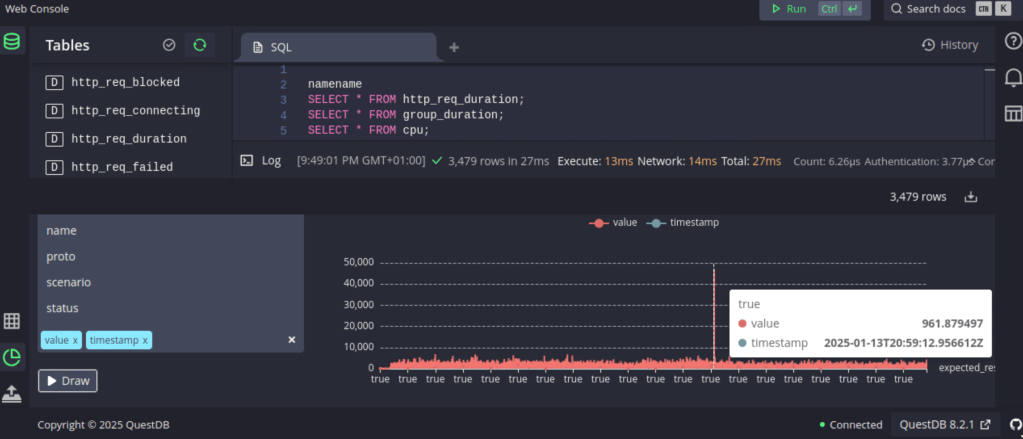
The base app was made in a few hours, after that has it been extended and improved, It’s built with Python, using Streamlit for UI, selected QuestDB for high performance database, uses stock data from Alpaca, Polygon and NewsAPI, able to run locally on a Mac (Apple Silicon) and as scalable server on Linux, (can also be deployed to Cloud) which is intended to be using (a prototype already exists, more of that later) multithreading to concurrently read stock data from a long list and pass it on to the FPGA that will process the data in around 300ns timeframe to locate stocks with the right strategy match and issue an order if risk management passes.
Cursor was used to generate code and test procedures, the generated code didn’t always work until a few rounds had been made to correct errors, one problem is that Cursor breaks the code quite often when a code change is introduced.
Deepseek-R1 is used to analyse stock news information based on the provided symbol collected from NewsAPI. The main use of the app is to work out a strategy that is intended be tailored for the unique platform and infrastructure in terms of performance/timings and


The AI part (Deepseek-r1:1.5b on MacBook Pro (M1/M2) on Linux server is 7b model currently being tested) is used excessively to analyse news information and report generation, it’s quite fast on the Mac (M1/M2), depending on the select stock symbol of course AAPL (Apple) for example will take much longer (currently 30s (M1)) due to the amount of data to analyse compared to a very small almost unknown company, a preprocessing step may be good idea to implement here, therefore it’s designed to be run in the background and the GPU performance will highly depend on the elapsed time
News Analysis by AI

News API (short)

Analysis

Risk Management

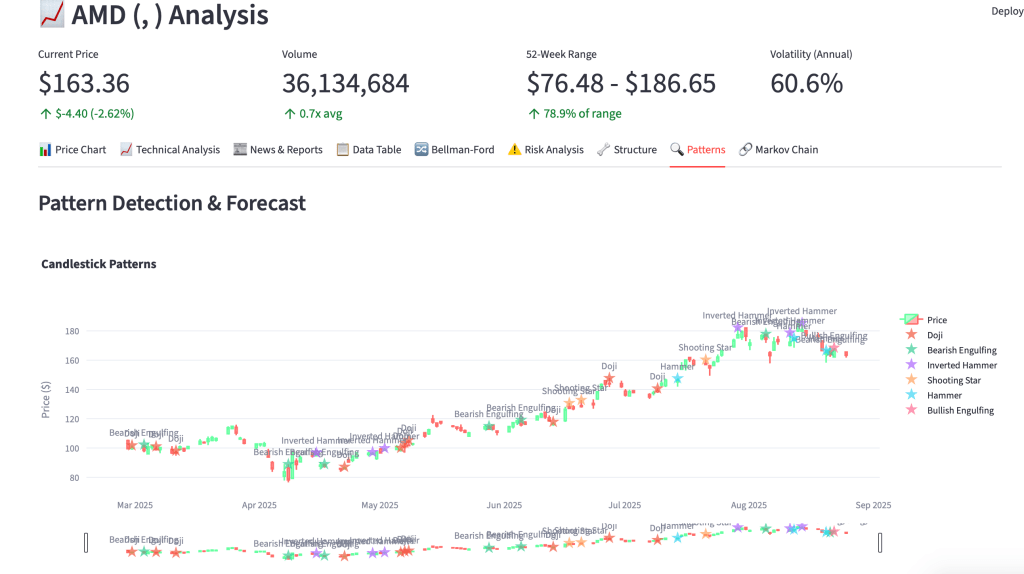
Patterns
Future ahead

(no AI was used to write this text)
Coming up: Real-time data against FPGA to stress analytics and latency/timings